Nats io


INTRODUCTION
NATS (pronounced "nats") is a lightweight and high-performance messaging system designed for building distributed and scalable applications. It follows a publish-subscribe (pub/sub) and request-reply messaging pattern and is known for its simplicity, speed, and reliability.
NATS.io is a connective technology for distributed systems and is a perfect fit to connect devices, edge, cloud or hybrid deployments. True multi-tenancy makes NATS ideal for SaaS and self-healing and scaling technology allows for topology changes anytime with zero downtime.
What is NATS
Software applications and services need to exchange data. NATS is an infrastructure that allows such data exchange, segmented in the form of messages. We call this a "message-oriented middleware".
Cloud Native Messaging System
Performance, simplicity , security and availability
Multiple communication patterns
30-client language support
With NATS, application developers can:
Effortlessly build distributed and scalable client-server applications.
Store and distribute data in real time in a general manner. This can flexibly be achieved across various environments, languages, cloud providers and on-premises systems.
NATS Client Applications
Developers use one of the NATS client libraries in their application code to allow them to publish, subscribe, request and reply between instances of the application or between completely separate applications. Those applications are generally referred to as 'client applications' or sometimes just as 'clients' throughout this manual (since from the point of view of the NATS server, they are clients).
NATS Service Infrastructure
The NATS services are provided by one or more NATS server processes that are configured to interconnect with each other and provide a NATS service infrastructure. The NATS service infrastructure can scale from a single NATS server process running on an end device (the nats-server process is less than 20 MB in size!) all the way to a public global super-cluster of many clusters spanning all major cloud providers and all regions of the world such as Synadia's NGS.
Connecting NATS Client applications to the NATS servers
To connect a NATS client application with a NATS service, and then subscribe or publish messages to subjects, it only needs to be configured with:
1.URL: A 'NATS URL'. This is a string (in a URL format) that specifies the IP address and port where the NATS server(s) can be reached, and what kind of connection to establish (plain TCP, TLS, or Websocket).
2.Authentication (if needed): Authentication details for the application to identify itself with the NATS server(s). NATS supports multiple authentication schemes (username/password, decentralized JWT, token, TLS certificates and Nkey with challenge).
Simple messaging design
NATS makes it easy for applications to communicate by sending and receiving messages. These messages are addressed and identified by subject strings, and do not depend on network location.
Data is encoded and framed as a message and sent by a publisher. The message is received, decoded, and processed by one or more subscribers.

With this simple design, NATS lets programs share common message-handling code, isolate resources and interdependencies, and scale by easily handling an increase in message volume, whether those are service requests or stream data.
How to use .
Nats io have different way of installation of server according to your need
But in this post we use nats cli.
Nats CLI
A command line utility to interact with and manage NATS.
This utility replaces various past tools that were named in the form nats-sub and nats-pub, adds several new capabilities and support full JetStream management.
Features
Simplicity
Wild card subscribers
Fanout
Load Balanced
Request /Reply
Publish / Subscribe
Selfish optimzation -protect against slow consumers
Self healing server-client connections - tone
publisher rate limiting
Streams
JetStream management
JetStream data and configuration backup
Message publish and subscribe
Service requests and creation
Benchmarking and Latency testing
Super Cluster observation
Configuration context maintenance
NATS eco system schema registry
Installation
For Mac os brew can be used
brew tap nats-io/nats-tools
brew install nats-io/nats-tools/nats
For windows or other operating system
Just download nats-0.0.34-windows-amd64.zip from natscli release page and extract nats.exe wherever you want.
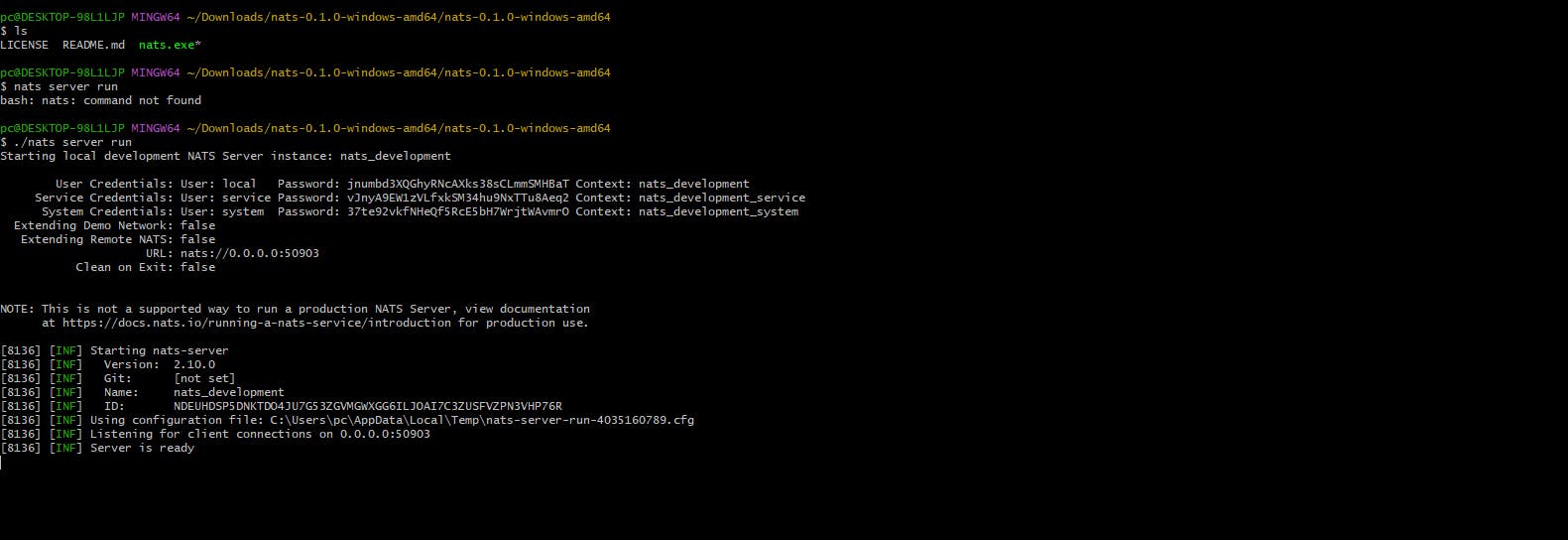
Lets Start with quick start nats server
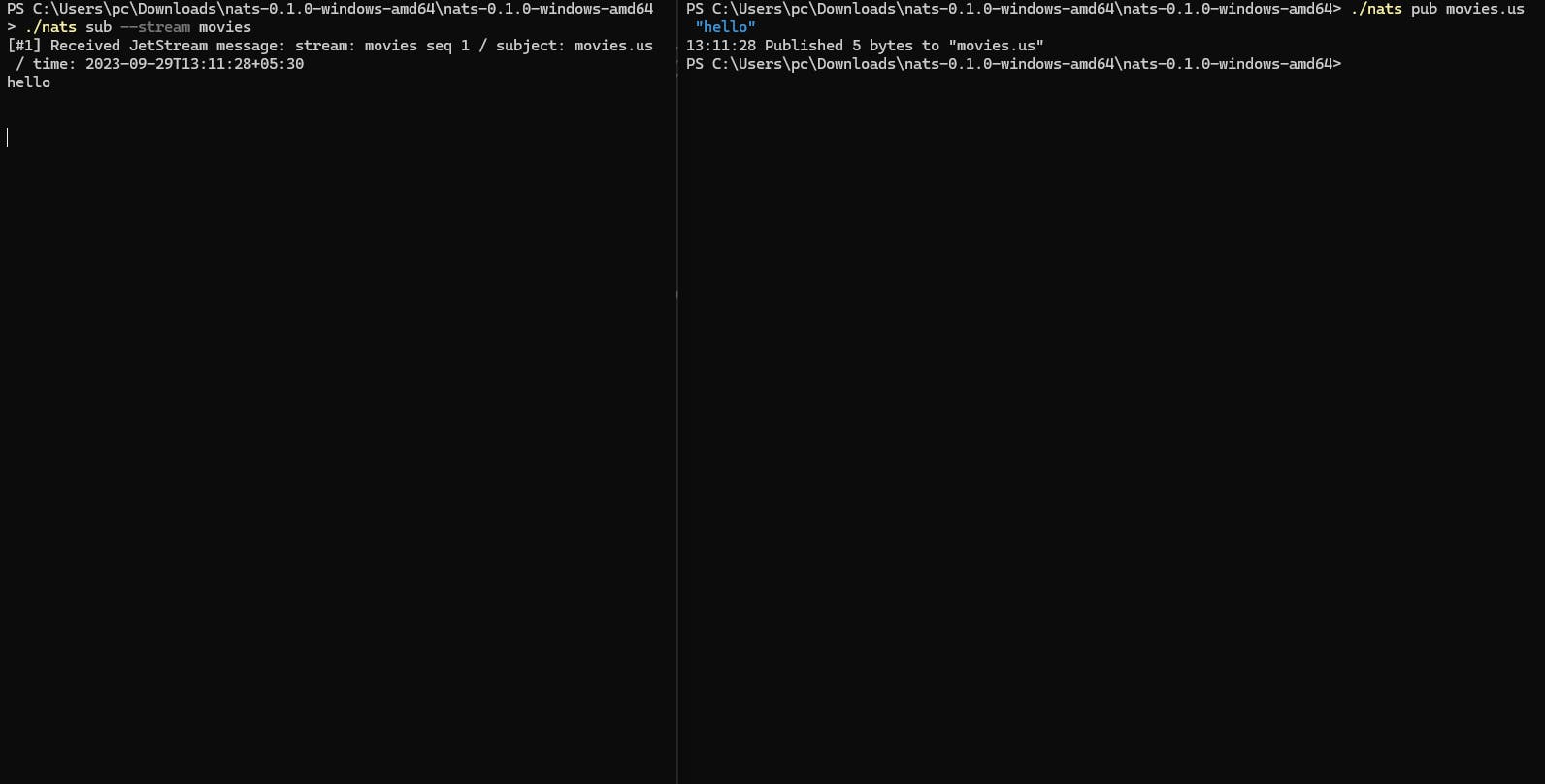
Lets publish a message with topic name
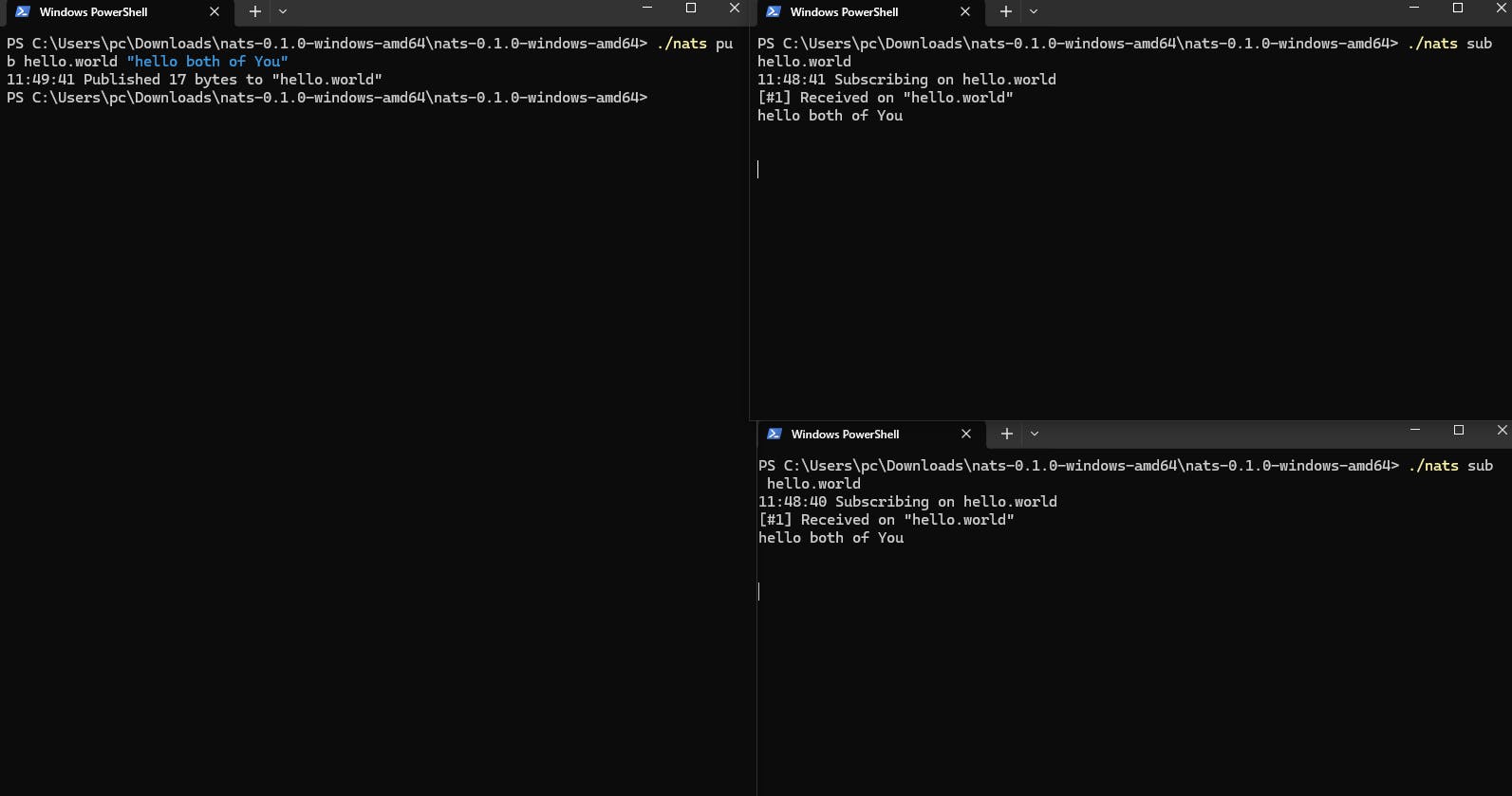
pub: This is a subcommand or argument to thenatscommand, indicating that you want to publish (send) a message.hello.world: This is the subject or topic to which you want to publish the message. In NATS, subjects are used to categorize and route messages to subscribers. In this case, you are publishing the message to the "hello.world" subject."hello": This is the message payload or content that you want to publish. It's the actual data you are sending to the "hello.world" subject.sub: This is a subcommand or argument to thenatscommand, indicating that you want to subscribe to (receive) messages from a specific subject.here is the more details of subject based messaging SBM

Wildcards
NATS provides two wildcards that can take the place of one or more elements in a dot-separated subject. Subscribers can use these wildcards to listen to multiple subjects with a single subscription but Publishers will always use a fully specified subject, without the wildcard.
Matching A Single Token
The first wildcard is * which will match a single token. For example, if an application wanted to listen for eastern time zones, they could subscribe to time.*.east, which would match time.us.east and time.eu.east.

Matching Multiple Tokens
The second wildcard is > which will match one or more tokens, and can only appear at the end of the subject. For example, time.us.> will match time.us.east and time.us.east.atlanta, while time.us.* would only match time.us.east since it can't match more than one token.

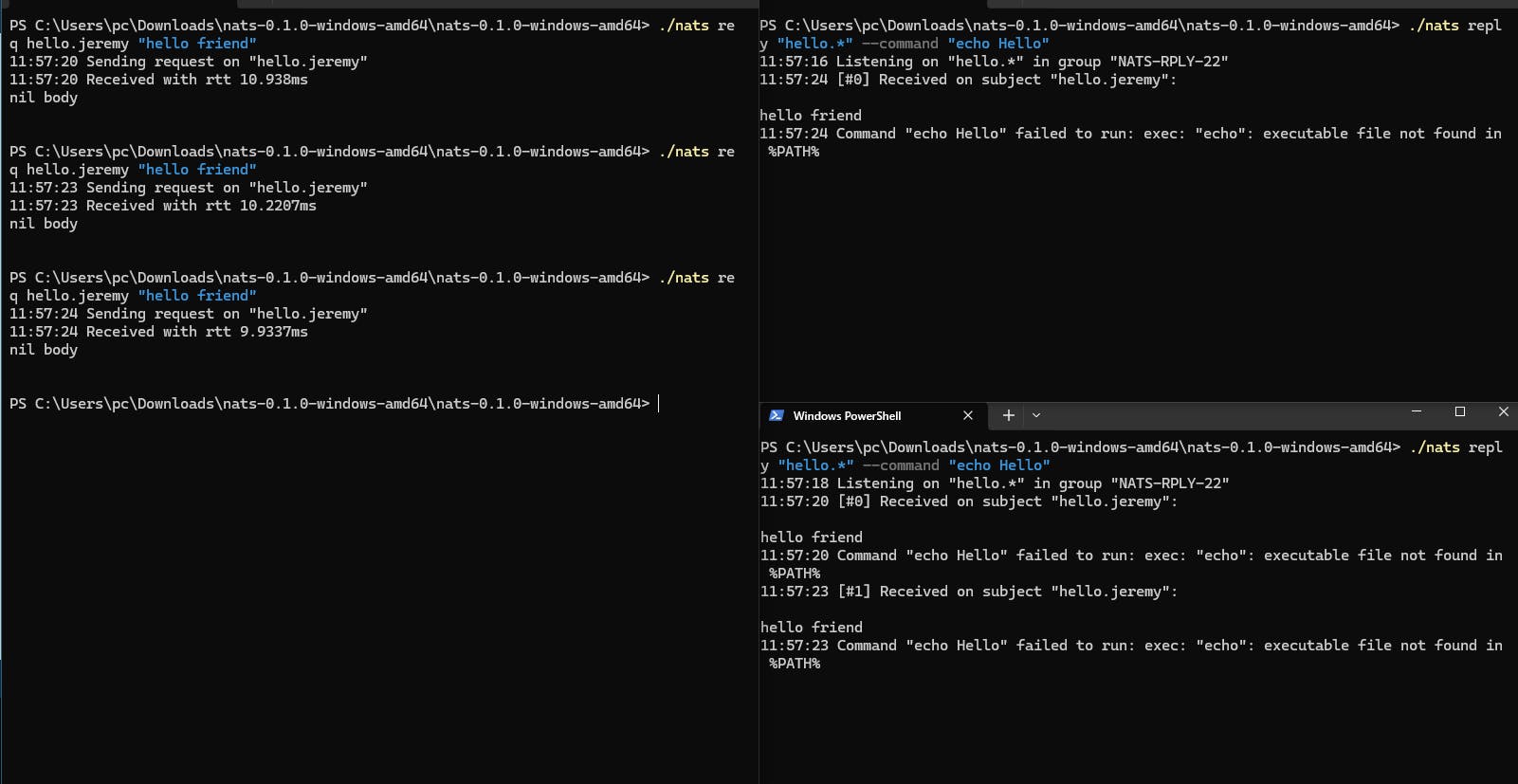
It will also act like a load balancer.
JetStream
NATS has a built-in distributed persistence system called JetStream which enables new functionalities and higher qualities of service on top of the base 'Core NATS' functionalities and qualities of service.
JetStream is built-in to nats-server and you only need 1 (or 3 or 5 if you want fault-tolerance against 1 or 2 simultaneous NATS server failures) of your NATS server(s) to be JetStream enabled for it to be available to all the client applications.
JetStream was created to solve the problems identified with streaming in technology today - complexity, fragility, and a lack of scalability. Some technologies address these better than others, but no current streaming technology is truly multi-tenant, horizontally scalable, and supports multiple deployment models. No other technology that we are aware of can scale from edge to cloud under the same security context while having complete deployment observability for operations.
Goals
JetStream was developed with the following goals in mind:
The system must be easy to configure and operate and be observable.
The system must be secure and operate well with NATS 2.0 security models.
The system must scale horizontally and be applicable to a high ingestion rate.
The system must support multiple use cases.
The system must self-heal and always be available.
The system must allow NATS messages to be part of a stream as desired.
The system must display payload agnostic behavior.
The system must not have third party dependencies.
Functionalities enabled by JetStream
Streaming: temporal decoupling between the publishers and subscribers
One of the tenets of basic publish/subscribe messaging is that there is a required temporal coupling between the publishers and the subscribers: subscribers only receive the messages that are published when they are actively connected to the messaging system (i.e. they do not receive messages that are published while they are not subscribing or not running or disconnected). The traditional way for messaging systems to provide temporal decoupling of the publishers and subscribers is through the 'durable subscriber' functionality or sometimes through 'queues', but neither one is perfect:
durable subscribers need to be created before the messages get published
queues are meant for workload distribution and consumption, not to be used as a mechanism for message replay.
Limits
You can impose the following limits on a stream
Maximum message age.
Maximum total stream size (in bytes).
Maximum number of messages in the stream.
Maximum individual message size.
You can also set limits on the number of consumers that can be defined for the stream at any given point in time
Read More for Jetstream here
Streams
Streams are 'message stores', each stream defines how messages are stored and what the limits (duration, size, interest) of the retention are. Streams consume normal NATS subjects, any message published on those subjects will be captured in the defined storage system. You can do a normal publish to the subject for unacknowledged delivery, though it's better to use the JetStream publish calls instead as the JetStream server will reply with an acknowledgement that it was successfully stored.
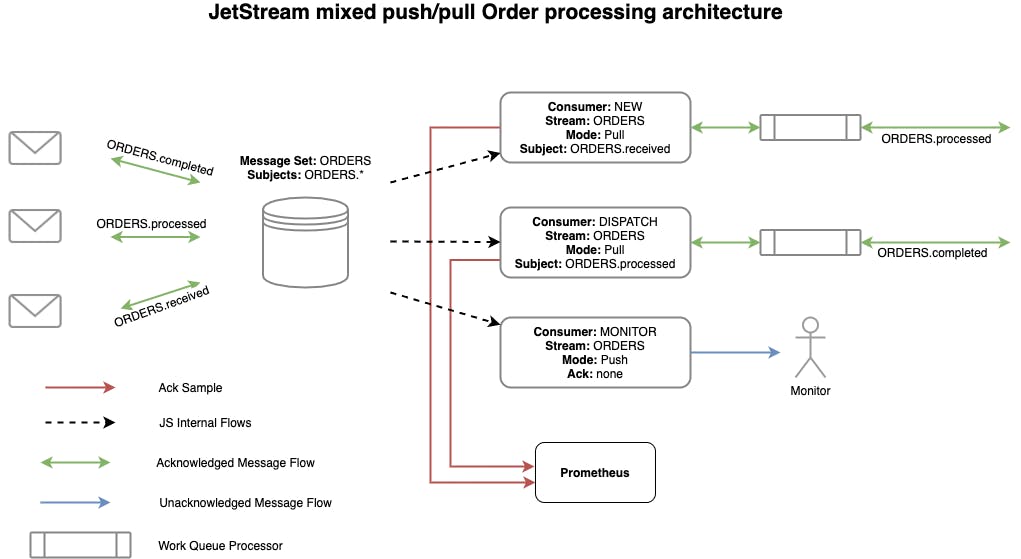
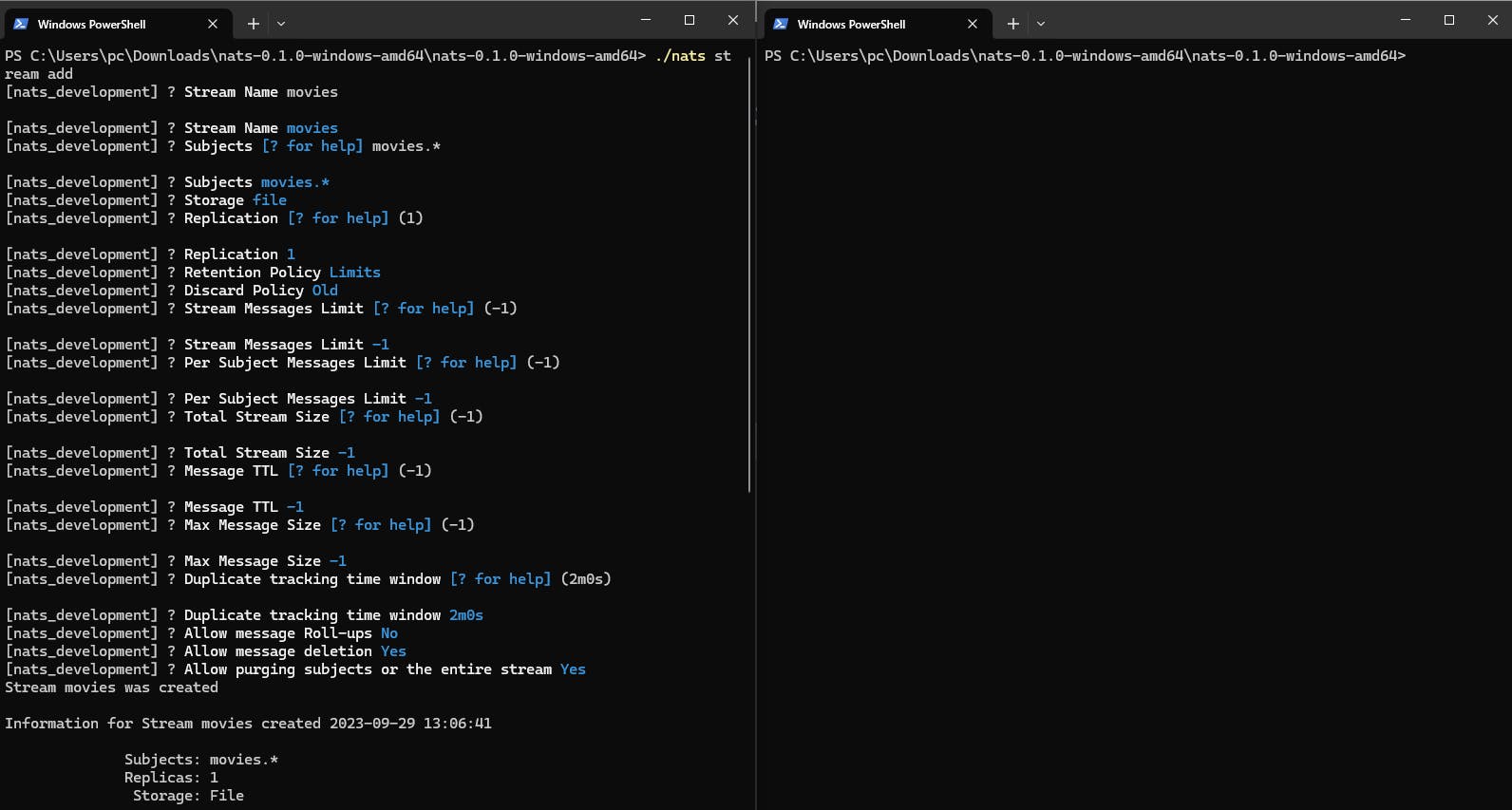
Lets Create Stream
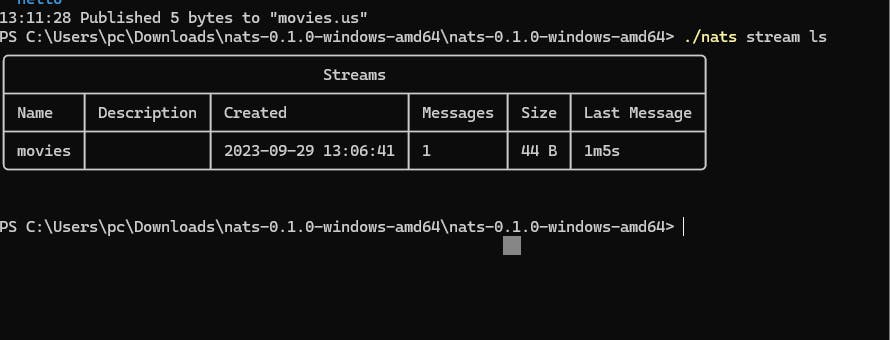
- You can check with command nats stream ls to show how many message is generated and status of stream
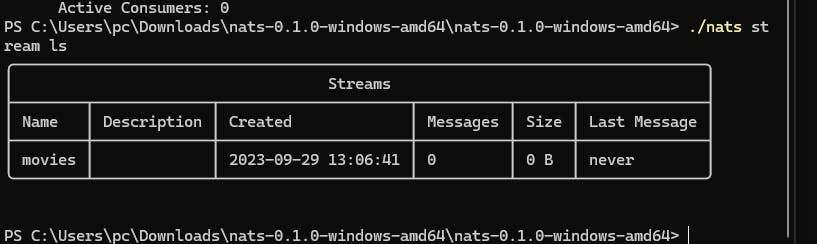
- Messsage is stored.
More commands and functionalities can be used here is the link
Now lets discuss which is best in term of Distriubted Messaging System
NATS was originally built with Ruby and achieved a respectable 150k messages per second. The team rewrote it in Go, and now you can do an absurd 8–11 million messages per second. It works as a publish-subscribe engine, but you can also get synthetic queuing.
Pros:
Slogan: always on and available, dial tone
Concise design
Low CPU-consuming
Fast: Ahigh-velocity communication bus
High availability
High scalability
Light-weight: It’s tiny, just a 3MB Docker image!
Once deployment
Cons:
Fire and forget, no persistence: NATS doesn’t do persistent messaging; if you’re offline, you don’t get the message.
No transaction
No enhanced delivery modes
No enterprise queueing
Key Features:
Lightweight and high-performance pub/sub messaging system
Simplicity and ease of use with a small footprint and minimal configuration
At-least-once message delivery with NATS Streaming
Support for request-reply and point-to-point messaging patterns
Clustering and fault tolerance capabilities
Use Cases:
Real-time event streaming and notifications
Microservices and serverless communication
Cloud-native applications and container orchestration
IoT and edge computing
Performance Metrics:
Supports hundreds of thousands to millions of messages per second, depending on hardware and configuration
Average end-to-end latency in the microseconds to milliseconds range
In general, NATS and Redis are better suited to smaller messages (well below 1MB), in which latency tends to be sub-millisecond up to four nines.
NATS is not HTTP, it’s its own very simple text-based protocol, RPC-like. So it does not add any header to the message envelope.
RabbitMQ:
RabbitMQ is a messaging engine that follows the AMQP 0.9.1 definition of a broker. It follows a standard store-and-forward pattern where you have the option to store the data in RAM, on disk, or both. It supports a variety of message routing paradigms. RabbitMQ can be deployed in a clustered fashion for performance, and mirrored fashion for high availability. Consumers listen directly on queues, but publishers only know about “exchanges.” These exchanges are linked to queues via bindings, which specify the routing paradigm (among other things). RabbitMQ does persist messages to disk. https://www.rabbitmq.com/persistence-conf.html
Unlike NATS, it’s a more traditional message queue in the sense that it supports binding queues and transactional-delivery semantics.
Consequently, RabbitMQ is a more “heavyweight” queuing solution and tends to pay an additional premium with.
Key Features:
Flexible and extensible message broker supporting multiple messaging protocols, including AMQP, STOMP, and MQTT
Supports various messaging patterns, such as pub/sub, request-reply, and point-to-point
Highly configurable and pluggable, with a rich plugin ecosystem
Advanced message routing capabilities with exchanges and queues
Clustering and high availability options
Use Cases:
Application integration and communication
Task distribution and workload balancing
Microservices communication and coordination
IoT and real-time applications
Performance Metrics:
Supports thousands to tens of thousands of messages per second, depending on hardware and configuration
Average end-to-end latency in the sub-millisecond to milliseconds range
Cons:
RabbitMQ’s high availability support is terrible. It’s a single point of failure no matter how you turn it because it cannot merge conflicting queues that result from a split-brain situation. Partitions can happen not just on network outage, but also in high-load situations.
Kafka
With Kafka, you can do both real-time and batch processing. Kafka runs on JVM (Scala to be specific). Ingest tons of data, route via publish-subscribe (or queuing). The broker barely knows anything about the consumer. All that’s really stored is an “offset” value that specifies where in the log the consumer left off.
Unlike many integration brokers that assume consumers are mostly online, Kafka can successfully persist a lot of data and supports “replay” scenarios.
The architecture is fairly unique; Topics are arranged in partitions (for parallelism), and partitions are replicated across nodes (for high availability).
Kafka is used by Unicorn startups, IOT, health, and large financial organizations ( LinkedIn, FB, Netflix, GE, Bank OF America, Fannie Mae, Chase Bank .. and so on…)
NATS is a very small infrastructure compared to Kafka. Kafka is more matured compared to Nats and performs very well with huge data streams.
NATS Server has a subset of the features in Kafka as it is focused on a narrower set of use cases.
NATS has been designed for scenarios where high performance and low latency are critical but losing some data is fine if needed in order to keep up with data-what the NATS documentation describes as “fire and forget”. Architecturally, that’s because NATS doesn’t have a persistence layer to use to store data durably.
While Kafka does have a persistence layer (using storage on the cluster).
To fully guarantee that a message won’t be lost, it looks like you need to declare the queue as durable + to mark your message as persistent + use publisher confirms. And this costs several hundreds of milliseconds of latency.
The only queue or pub/sub system that is relatively safe from partition errors is Kafka. Kafka is just a really solid piece of engineering when you need 5–50 servers. With that many servers, you can handle millions of messages per second that usually enough for a mid-size company.
Kafka is completely unsuitable for RPC, for several reasons. First, its data model shards queues into partitions, each of which can be consumed by just a single consumer. Assume we have partitions 1 and 2. P1 is empty, P2 has a ton of messages. You will now have one consumer C1 which is idle, while C2 is doing work. C1 can’t take any of C2’s work because it can only process its own partition. In other words: A single slow consumer can block a significant portion of the queue. Kafka is designed for fast (or at least evenly performant) consumers.
Key Features:
Distributed and highly-scalable pub/sub messaging system
Fault-tolerant and durable, with built-in replication and partitioning
High throughput and low-latency message processing
Stream processing capabilities with Kafka Streams
Strong durability guarantees with write-ahead logs
Use Cases:
Log aggregation and processing
Real-time data analytics and monitoring
Event sourcing and CQRS
Stream processing and data integration
Performance Metrics:
Supports millions of events per second, depending on hardware and configuration
Average end-to-end latency in the milliseconds range
NATS vs. Kafka
NATS recently joined CNCF (which hosts projects like Kubernetes, Prometheus etc. — look at the dominance of Golang here!)
Protocol — Kafka is binary over TCP as opposed to NATS being simple text (also over TCP)
Messaging patterns — Both support pub-sub and queues, but NATS supports request-reply as well (sync and async)
NATS has a concept of a queue (with a unique name of course) and all the subscribers hooked on the same queue end up being a part of the same queue group.
Only one of the (potentially multiple) subscribers gets the message. Multiple such queue groups would also receive the same set of messages. This makes it a hybrid pub-sub (one-to-many) and queue (point-to-point). The same thing is supported in Kafka via consumer groups which can pull data from one or more topics.
Stream processing — NATS does not support stream processing as a first-class feature like Kafka does with Kafka Streams
Kafka clients use a poll-based technique in order to extract messages as opposed to NATS where the server itself routes messages to clients (maintains an interest graph internally).
NATS can act pretty sensitive in the sense that it has the ability to cut off consumers who are not keeping pace with the rate of production as well as clients who don’t respond to heartbeat requests.
The consumer liveness check is executed by Kafka as well. This is done/initiated by the client itself & there are complex situations that can arise due to this (e.g. when you’re in a message processing loop and don’t poll ).
There are a bunch of configuration parameters/knobs to tune this behavior (on the client side)
Delivery semantic — NATS supports at most once (and at least once with NATS streaming) as opposed to Kafka which also supports exactly once (tough!)
NATS doesn’t seem to have a notion of partitioning/sharding messages like Kafka does
No external dependency in the case of NATS. Kafka requires Zookeeper
NATS Streaming seems to be similar to the Kafka feature set, but built using Go and looks to be easier to set up.
NATS does not support replication (or really any high availability settings) currently. Which is a major missing feature when comparing it to Kafka.
Kafka — Pros
Mature: very rich and useful JavaDoc
Kafka Streams
Mature & broad community
Simpler to operate in production — less components — broker node provides also storage
Transactions — atomic reads&writes within the topics
Offsets form a continuous sequence — consumer can easily seek to last message
Kafka — Cons
Consumer cannot acknowledge message from a different thread
No multitenancy
No robust Multi-DC replication — (offered in Confluent Enterprise)
Management in a cloud environment is difficult.
Apache Pulsar
It was designed at Yahoo as a high-performance, low latency, scalable, durable solution for both pub-sub messaging and message queuing.
Apache Pulsar combines high-performance streaming (which Apache Kafka pursues) and flexible traditional queuing (which RabbitMQ pursues) into a unified messaging model and API. Pulsar gives you one system for both streaming and queuing, with the same high performance, using a unified API. To sum up, Kafka aims for high throughput, Pulsar for low latency.
Pulsar — Pros
Feature rich — persistent/nonpersistent topics, multitenancy, ACLs, Multi-DC replication etc.
More flexible client API that is easier to use — including CompletableFutures, fluent interfaces etc.
Java client components are thread-safe — a consumer can acknowledge messages from different threads. Java client has Javadoc (https://pulsar.apache.org/api/client/)
Community — 8 stackoverflow questions currently and https://pulsar.apache.org/powered-by/
Pulsar — Cons
MessageId concept tied to BookKeeper — consumers cannot easily position itself on the topic compared to Kafka offset which is a continuous sequence of numbers.
A reader cannot easily read the last message on the topic — need to skim through all the messages to the end. Note on 20190106: It can position a reader on the latest message.
No transactions (20190106: Transaction support is planned for 2.6 release)
Higher operational complexity — Zookeeper + Broker nodes + BookKeeper — all clustered
Latency questionable — there is one extra remote call between Broker node and BookKeeper (compared to Kafka), so we can run broker and bookkeeper in the same node if required.
Conclusion
Selecting the right message broker for your event-driven architecture depends on your specific requirements, such as performance, scalability, durability, and messaging patterns. Apache Kafka is a great choice for large-scale, distributed systems that require high throughput and strong durability guarantees. RabbitMQ offers flexibility and advanced routing capabilities, making it suitable for a wide range of applications, including microservices and IoT. Finally, NATS is ideal for scenarios where simplicity, performance, and lightweight design are paramount, such as real-time applications and edge computing.
More compare Information are available here https://docs.nats.io/nats-concepts/overview/compare-nats